

平台定位:由于心理数据包含了用户的大量隐私信息,因此心理数据不能直接共享使用,中心研发了多模态心理数据挖掘平台,旨在解决心理学数据的安全共享和使用问题,通过差分隐私、区块链、隐私域防控理论等关键技术,实现共享数据的价值而不共享数据本身,科研人员可以看到共享数据的元数据信息,但看不到具体数据,通过元数据描述信息以及内置的上百种数据挖掘方法实现线上数据挖掘,本平台是中心实现“校-医”协同的重要手段和支撑。
访问地址:https://47.93.247.187:8765
账号:test01
密码:123456
入门教程
一、统计分析
1. 创建分析项目
此部分使用【情绪识别】数据集进行演示。首先在左侧菜单栏点击【项目管理】进入项目页面,点击右侧上方【新增】按钮,设置项目相关信息。如果项目已经存在,可以点击项目【查看】按钮进入项目。
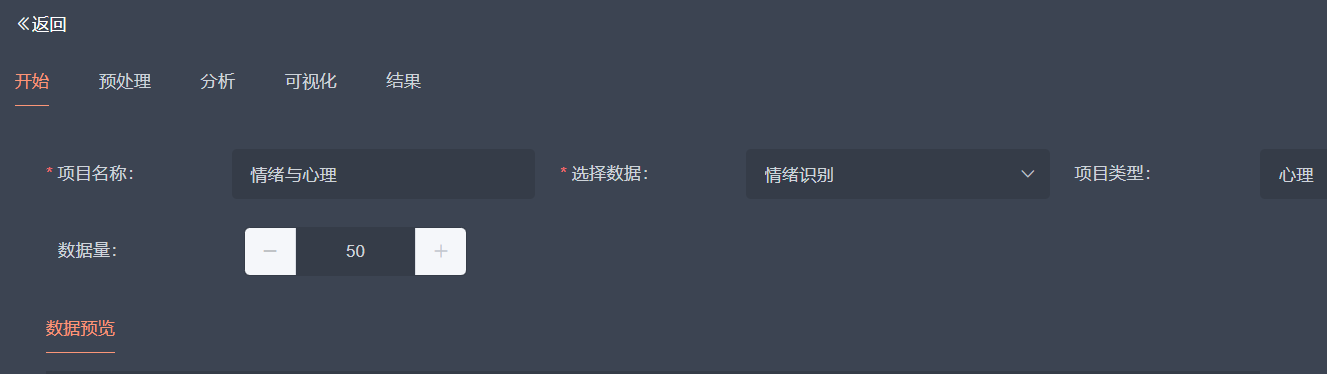
填写相关信息后,在下方【数据预览】表单中勾选用于后续分析的数据字段,然后点击下一步。
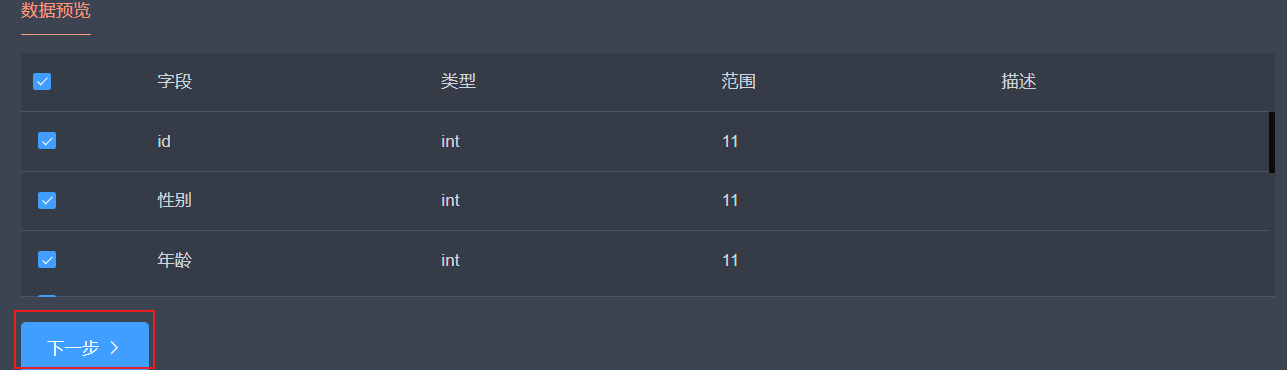
在数据预处理阶段,可以对勾选的字段进行数据类型转换等相应的数据预处理操作:
字段预处理设置完成后在页面最下方点击【下一步】进入方法选择页面,我们将演示以下相关的分析内容:
2、基础统计分析
在【方法选择】中选择“统计分析”,“频数统计”选项,【输入数据】选择年龄(age)字段,【输入类型】选择“continuous (连续型)”,【类别数量】设置为3,或者【输入数据】选择性别(gender)字段,【输入类型】选择“discrete(离散型)”,【类别数量】设置为2。
输入【输出字段命名】和【图表信息】,点击【提交执行】。稍等方法执行完后获得执行结果,点击右侧可以查看结果图像,点击【保存结果】可以将执行结果和图像保证在当前项目中。
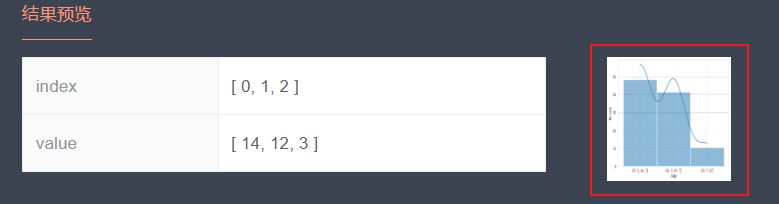
由于方法执行为了能够快速直观地展示算法结果,输出的图表通常基于固定样式,有时不能满足于使用需求,因此针对这一情况,点击页面的【下一步】按钮进入【可视化】页面可以针对当前方法产生的数据进一步绘制图像。
在可视化页面中,我们在【数据选择】中勾选需要绘制图像的数据,上一步方法执行的结果数据通常在表单的最后一行。然后点击【获取数据】来获得相应的数据用于生成图像。
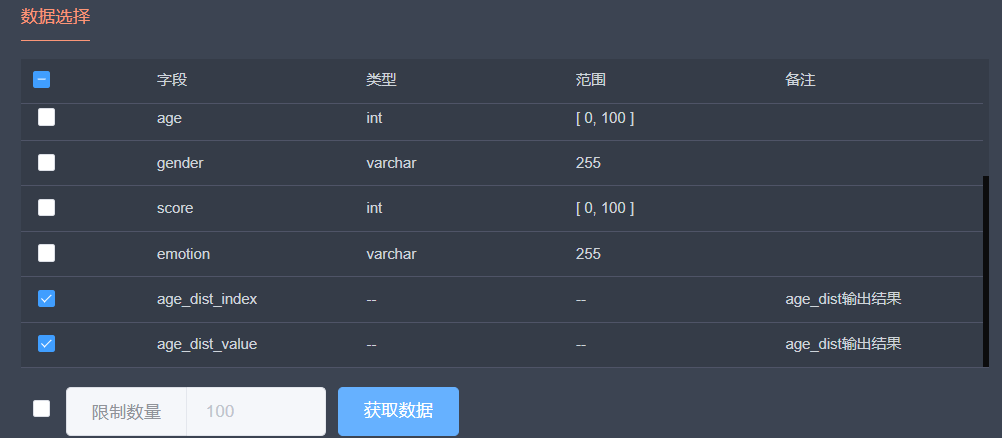
在下方图像相似部分的右侧可以图表的相关设置,此处我们选择“饼图”来展示年龄分布的占比情况,并设置图片的标题的相关信息,获得如下图像。
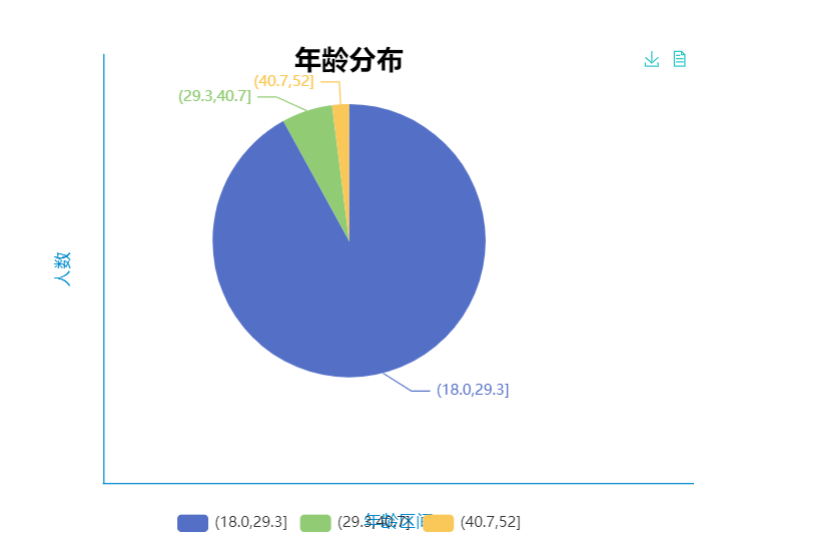
对应设置完成的图像,通过【图表配置】下方的【保存配置信息】可以将当前图表和配置保证在项目中。
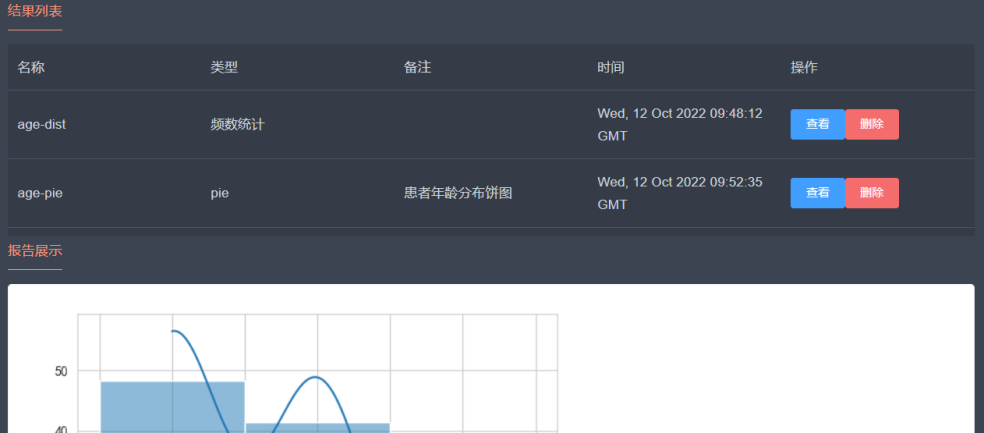
最后点击【下一步】进入结果页面,可以查看前面两步中保存的结果信息和图表内容。
3. 情绪类别分析
同样的方法还可以将人员年龄、情绪等特征进行人员情绪类别的分析,采用kmeans聚类,结果显示可以将参与情绪识别的人员根据情绪聚类为两种类别。

二、数据挖掘
此部分使用【心理测评量表】数据集进行演示。首先在左侧菜单栏点击【项目管理】进入项目页面,点击右侧上方【新增】按钮,设置项目相关信息。如果项目已经存在,可以点击项目【查看】按钮进入项目。
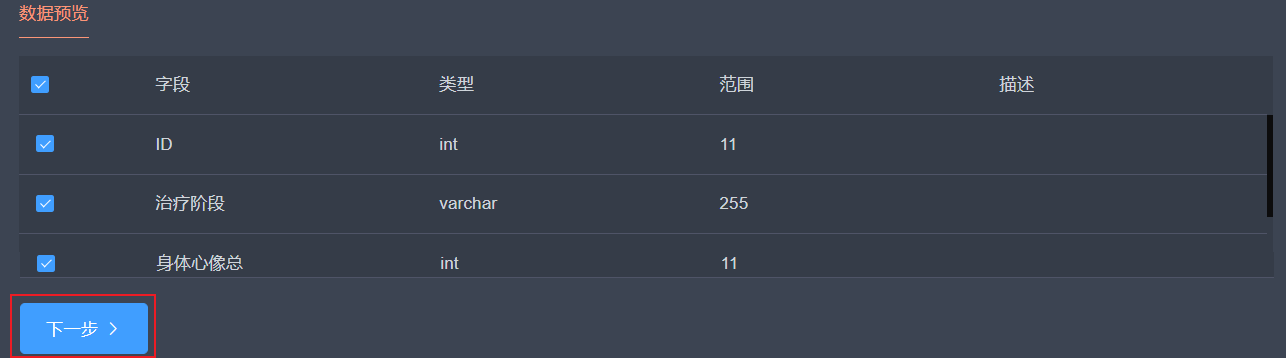
填写相关信息后,在下方【数据预览】表单中勾选用于后续分析的数据字段,然后点击下一步。
在数据预处理阶段,可以对勾选的字段进行数据类型转换等相应的数据预处理操作:

字段预处理设置完成后在页面最下方点击【下一步】进入方法选择页面,我们将演示以下相关的分析内容:
1、数据假设检验
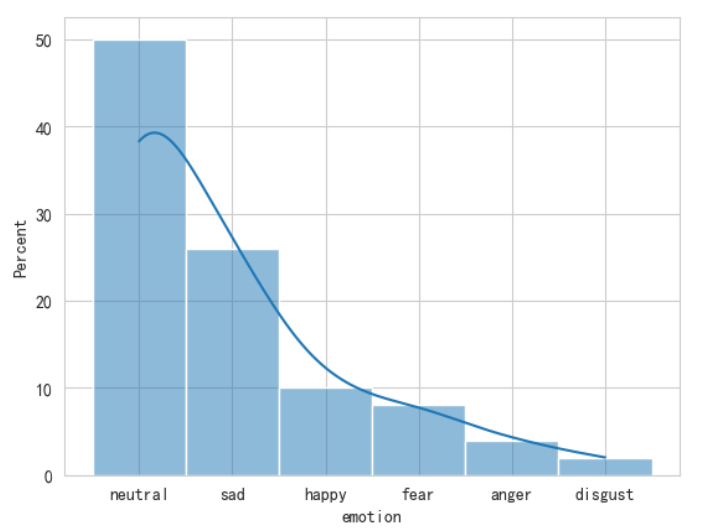
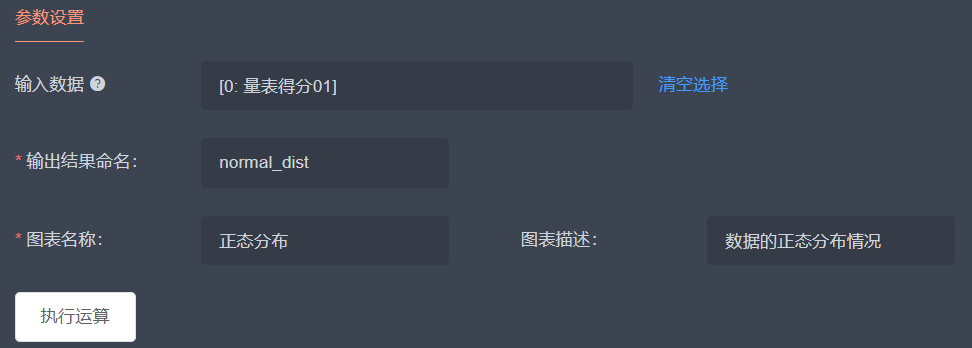
通常在使用采集的数据进行数据挖掘时,会验证数据分布是否合理,避免长尾数据影响分析的效果和准确率。此处我们使用正态性检验对采集的数据进行正态性检验。在【方法选择】中选择“统计分析”,“正态性检验”选项,【输入数据】选择“量表得分01”字段,或其他字段,输入【输出字段命名】和【图表信息】,点击【提交执行】。
在假设检验中,数据结果中通常会包括p-value,反映某一事件发生的可能性大小。原假设样本数据服从正态分布,当p值小于某个显著性水平α(如0.05),则认为样本不是来自正态分布的总体。

方法执行完后获得执行结果,点击右侧可以查看结果图像。可以看到得出的P值等于,通常认为此时应该拒绝原假设,即分布不满足正态分布,经过查证这个原因是这组数据是贡献者随机生成的假数据,没有按照正态分布生成。点击【保存结果】可以将执行结果和图像保证在当前项目中。
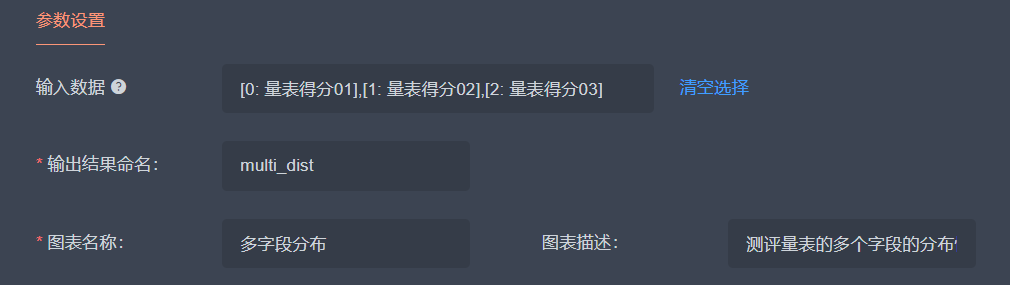
前面展示了对于单一数据字段的统计分析,针对于多个字段的分布情况对比,可以在【方法】页面,选择“统计分析”,“数据分布”选项,【输入数据】选择多个数值型字段。
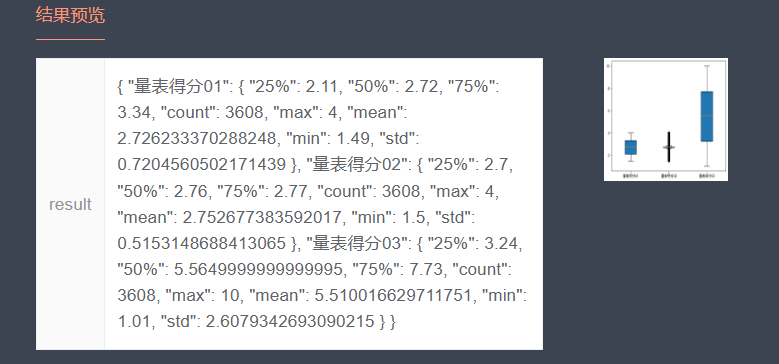
2、逻辑回归
演示回归分析算法在此数据集的应用,我们在【方法选择】中选择“分类方法”,“逻辑回归”选项,【输入数据】选择[“id”,“年龄”,“量表得分01”,“量表得分02”,“量表得分03”,“y_label”]几个特征字段,【预测字段】选择“y_label”,【测试比例】设置为0.2,C设置为0.5,其他参数默认,输入【输出字段命名】和【图表信息】,点击【提交执行】。
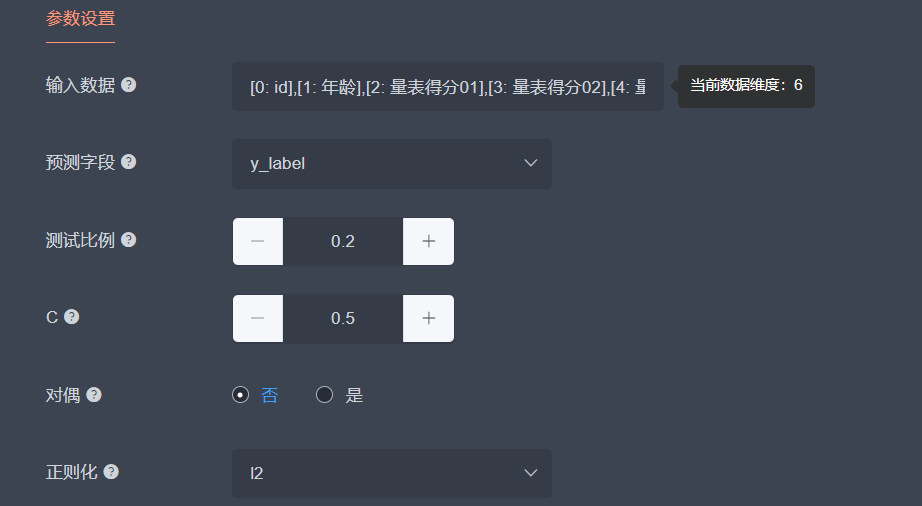
稍等方法执行完后获得执行结果,此时获得了患者抑郁评价与多个影响因子特征之间的预测结果,模型预测准确率分数约为0.96。点击右侧可以查看结果图像,点击【保存结果】可以将执行结果和图像保证在当前项目中。进一步地,可以更换不同的回归方法,对比不同算法之间的准确率。

同样,也可以在“分类方法”中选择其他方法尝试分类效果。

电话:0516-83262582 邮箱:CPCPI@xzhmu.edu.cn
地址:江苏徐州铜山路209号 邮编:221004
Copyright © 徐州医科大学心理健康教育中心 版权所有 苏ICP备10010028号